When the web was created, it had no memory. I don’t mean memory in the sense of kilobytes, megabytes, and gigabytes; I mean memory in the literal sense.
As you’ll recall from Chapter 1, a web browser requests a page from a web server. The server sends a response. This might be the first time that this particular browser has interacted with this particular server, or it might be the hundredth time. Without any memory of one another, they can never form a lasting relationship. Every time is just like the first time.
Because the word memory is already taken, we use the word state to describe these situations. A system that can retain knowledge of previous interactions is stateful. At its outset, the web was stateless.
Managing state can be tricky. The fact that the web was stateless kept it nice and simple. Anybody creating a new browser or new server software didn't have to worry about the arrow of time. But the stateless nature of the web was also frustrating. If you were trying to build a business on the web, you had no way of forming a relationship with your customers.
Imagine a user adding a product to their shopping cart, clicking on a link to another product, and finding their shopping cart empty again as though the past had never happened. An engineer at Netscape named Lou Montulli created cookies to remedy this problem. Such a cute-sounding name! And indeed, cookies are dainty little things—small pieces of text that can be stored by a browser and read by a server. Now that you can be identified by your cookie, a website can remember who you are, and what you’ve already put in your shopping basket. Unfortunately, cookies can also be used to track you from site to site, allowing advertising networks to build up a profile of your browsing habits.
Thanks to cookies, web servers can now identify and recall who you are. But how does a web browser remember that it has previously asked for a particular item from a web server? Caching!
The word cache always makes me think of pirates in Treasure Island talking about their secret caches of treasure. On the web, caches are also used to hoard precious items. Instead of storing doubloons and emeralds, we can use a cache to store files that we can dig up later.
Thinking about it like that, a “cache” is actually a pretty accurate term for the technology. It’s certainly sounds better than “booty.”
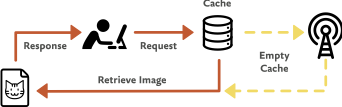
Suppose you’ve written a web page. In that page, you’ve included an image. As the browser parses your page, it sees that it needs to fetch an image, and off it goes to the server. Now suppose you include that same image again later in the same page. Instead of starting another request to the server, the browser realizes that it already has a copy of that image and reuses it (Fig 4.1).
That’s an example of the memory cache in action. It’s useful for avoiding duplicate server requests, but it only works for short-term interactions. Like a goldfish, the browser forgets about everything in its memory cache once the user leaves the page.
The browser has a longer-lasting store called the HTTP cache (or disk cache). If a file is stored in the HTTP cache, it can be retrieved and reused days, weeks, months, or even years later.
That sounds great, but you don’t actually want all your files to be stored in the HTTP cache. If a file is updated frequently—say, the homepage of your website—it would be disastrous if it were stored in the HTTP cache. Your site’s visitors would be served a stale version of the homepage.
The HTTP cache is really handy for files that are rarely, if ever, updated: images, fonts, stylesheets, and scripts. But you don’t want the HTTP cache to store web pages.
To avoid storing the wrong files, the HTTP cache only does what it’s told. It’s up to the web server to declare which kinds of files should be cached, and for how long. This is done through the exchange of HTTP headers—the secret, behind-the-scenes instructions that accompany every response. For instance, your web server can send max-age headers to tell the HTTP cache how long it should store certain files. The server tells the browser that it can store images, stylesheets, and scripts for months, but that HTML pages should never be stored.
Ah, but what if you update a stylesheet or script on the server? The browser is going to do what it has been told and reuse the old version from the HTTP cache. A visitor to your site will get stale CSS or JavaScript. The visitor can overcome this by performing a hard refresh (holding down Shift while reloading the page). But putting this burden on the visitor isn’t a great long-term strategy.
You could use max-age headers to instruct the browser to never store CSS or JavaScript files, but then you would miss out on the benefits of the HTTP cache. It would be a shame to force your site’s visitors to download the same CSS and JavaScript every single time they request a page.
The most common way of breaking this impasse is to change the names of the files themselves. Suppose someone visits one of your pages, and that page links to a stylesheet called styles-v1.css. Using headers, you can instruct the browser to cache that file for months. When you need to change the CSS, change the name of the file to something like styles-v2.css. As far as the browser is concerned, this is a brand-new file that bears no relation to the CSS file stored in the HTTP cache. The browser fetches the new file and then stores it in the HTTP cache for months.
The only downside to this approach is that you also have to update every HTML page that points to the CSS or JavaScript file that you’re changing the name of. On dynamic sites, there’s usually a build process in place to automate this.
The HTTP cache can really boost your site’s performance on repeat visits. It’s a fairly crude tool though, and you can’t entirely rely on it. Web browsers perform periodic clean-up operations, discarding files from the HTTP cache. There’s just one HTTP cache being shared by every single website that the browser visits. There’s only so much space to spare.
Now there’s a successor to the HTTP cache. Using the new Cache API, you have much more fine-grained control over the caching of your site’s content.
The Cache API is conceptually similar to the Fetch API. They are both APIs that give us access to the low-level features used by the browsers themselves. Browsers having been fetching and caching for decades, but now we can use those same mechanisms for our own purposes.
Like the Fetch API, the Cache API is asynchronous and uses promises to fulfill or reject each operation. That means you can use this API in your service worker script. You’ll be able to create caches, delete caches, put files into caches, and retrieve files from caches.
Don’t think of the Cache API as a replacement for the HTTP cache. Think of it as an enhancement. Don’t change whatever strategy you’re currently using for caching and versioning files. You can use the Cache API to create a powerful frontline caching strategy, but you will still want to keep the home fires burning with the HTTP cache.
Whereas the HTTP cache gives you one big cache for everything, the Cache API allows you to create separate caches. You could have one cache just for images, for example, and another cache for storing pages. Keeping your files in different caches gives you more control over how you treat those files.
Let’s start with a single cache for static assets—CSS, JavaScript, fonts, icons. These are all resources that are updated infrequently.
Open up your serviceworker.js file. At the top of the file, choose a name for your cache and store the name in a variable like this:
const staticCacheName = 'staticfiles'; I’m using const for this because the value of the variable shouldn’t be changed. Feel free to use a good old-fashioned var statement if you prefer. I’ve chosen to call this cache 'staticfiles' and assigned that name to the variable staticCacheName. You can give your cache any name you like. You could call it 'JohnnyCache'. Please don’t.
Now that you’ve got a name for your cache, you’ll want to create the cache and put files into it. But you’ll only want to do this once, when the service worker is first installed. You can listen out for an event called install.
addEventListener('install', installEvent => {
// Install-handling code goes here
});
This looks similar to how you’re listening for fetch events:
addEventListener('fetch', fetchEvent => {
// Fetch-handling code goes here
});
The difference is that the fetch event is triggered every single time the browser requests a resource, whereas the install event is only triggered when the service worker is first downloaded. You can tell the browser to delay the installation of the service worker until you’ve populated your cache. You’re saying, “When you’re about to install, wait until you’ve added these files to the static cache.” Translating that into JavaScript, you literally say waitUntil:
addEventListener('install', installEvent => {
installEvent.waitUntil(
// Cache your files here
); // end waitUntil
}); // end addEventListener
This is the moment to use the Cache API. You’ll start by using the open method of the caches object. This is a promise, so the structure looks like this:
caches.open(staticCacheName)
.then( cache => {
// Success!
})
.catch( error => {
// Failure!
});
There’s not much we can do about errors in this case, so we won’t even need to use the catch clause.
Put the caches.open method inside your install-handling code like this:
addEventListener('install', installEvent => {
installEvent.waitUntil(
caches.open(staticCacheName)
.then( staticCache => {
// Cache your files here
}) // end open then
); // end waitUntil
}); // end addEventListener
Now you have a reference—called staticCache—to the open cache. This has a method called addAll. You can pass an array of URLs into this method:
staticCache.addAll(array);
An array is a collection of items, separated with commas, and bookended with square brackets, like this:
[1,2,3,4]
That’s an array of four numbers, but you could also have an array of strings:
['John','Paul','George','Ringo']
For the addAll method, you’re going to pass in an array of strings. Each string is the URL of a file you want to cache.
staticCache.addAll([
'/path/to/stylesheet.css',
'/path/to/javascript.js',
'/path/to/font.woff',
'/path/to/icon.svg'
]);
Those URLs are fictitious. Any resemblance to actual URLs, living or dead, is purely coincidental. Make sure that you use real URLs. If just one item in the array is misspelt, none of the URLs will be cached.
Putting it all together, you will return the result of staticCache.addAll to the install event that’s patiently waiting with installEvent.waitUntil:
addEventListener('install', installEvent => {
installEvent.waitUntil(
caches.open(staticCacheName)
.then( staticCache => {
return staticCache.addAll([
'/path/to/stylesheet.css',
'/path/to/javascript.js',
'/path/to/font.woff',
'/path/to/icon.svg'
]); // end return addAll
}) // end open then
); // end waitUntil
}); // end addEventListener
By using that return statement, you’re making sure that the installation won’t be completed until all the items in the array have been cached. If there are lots of files, there’s a chance they won’t all get cached, and then the service worker won’t be installed.
To avoid that problem, you can split your list of files into the ones you must have and the ones you’d like to have. Put the must-haves behind the return statement. Put the nice-to-haves in a regular addAll:
addEventListener('install', installEvent => {
installEvent.waitUntil(
caches.open(staticCacheName)
.then( staticCache => {
// Nice to have
staticCache.addAll([
'/path/to/font.woff',
'/path/to/icon.svg'
]); // end addAll
// Must have
return staticCache.addAll([
'/path/to/stylesheet.css',
'/path/to/javascript.js'
]); // end return addAll
}) // end open then
); // end waitUntil
}); // end addEventListener
Now that you’ve successfully made a cache filled with your static assets, you can update your service worker script to take advantage of your cache. Here’s the logic of the code you’ll be writing:
It’s time to revisit your code for handling fetch events. This is the code that will run every single time the browser requests a file from your site.
addEventListener('fetch', fetchEvent => {
const request = fetchEvent.request;
fetchEvent.respondWith(
// fetch-handling code goes here
); // end respondWith
}); // end addEventListener
That takes care of the first part: “When the browser requests a file.”
Now for the next part: “look for a matching file that has been cached.” The long way of doing this is to use the open method of the caches object to specify which cache you want to search, and then use the match method to do the searching:
caches.open(staticCacheName)
.then( staticCache => {
return staticCache.match(request);
});
The short way is to use the match method directly on the caches object. You don’t need to specify which cache you want to look in:
caches.match(request);
As with all things cache-related, this is an asynchronous operation, so caches.match has the familiar structure of a promise:
caches.match(request)
.then( responseFromCache => {
// Success!
})
.catch( error => {
// Failure!
});
This seems straightforward enough. If we get a response from the cache, the promise is fulfilled and we can return that response. If we don’t get a response, then we can instead make a fetch request for the file within the catch clause, right?
Alas, no. If match doesn’t find a match for the file, the promise doesn’t reject. Instead, it returns a value of null in the then clause. This makes the catch clause as useful as a window washer on a submarine.
I have no idea why match has been designed to work this way. It’s like working with an annoyingly pedantic stickler.
“Hey!” you say to the Cache API. “Were you successful when you looked for this file?”
“Why, yes!” says the Cache API.
“Great!” you say. “Give it to me.” Whereupon the Cache API mimes handing something to you, because it has successfully found nothing.
When you’ve finished rolling your eyes, you’ll need to add an extra step to make sure the response isn’t empty:
caches.match(request)
.then( responseFromCache => {
if (responseFromCache) {
// Success!
}
})
When you write if (responseFromCache), that’s shorthand for if (responseFromCache !== null). Translated to English: “Is it not empty?”
Here’s how it looks inside your code:
addEventListener('fetch', fetchEvent => {
const request = fetchEvent.request;
fetchEvent.respondWith(
caches.match(request)
.then( responseFromCache => {
if (responseFromCache) {
return responseFromCache;
} // end if
}) // end match then
); // end respondWith
}); // end addEventListener
Notice how the return statement is used to pass the response up the chain from within caches.match to respondWith. The end result is that, if there’s a matching file in the cache, the fetch event responds with the contents of that file.
That takes care of the first two parts of the flow you’ve outlined:
Now it’s time to add the third and final part:
Here’s the code for that:
return fetch(request)
.then( responseFromFetch => {
return responseFromFetch;
});
In fact, you could shorten this code. Everything inside the then clause is telling the service worker to do what it would do anyway: return the response from fetching. So you can leave that part out, and the end result is the same:
return fetch(request);
If you want, you can put this in an else clause after the if statement:
if (responseFromCache) {
return responseFromCache;
} else {
return fetch(request);
}
In this case, the else wrapper isn’t necessary. Because the if block has a return statement within it, your fetch code can go right after the if block.
if (responseFromCache) {
return responseFromCache;
}
return fetch(request);
If you wanted to make your code even shorter, you could ditch the if statement entirely and use a single return statement:
return responseFromCache || fetch(request);
The two vertical lines mean “or,” so you’re saying, “Return the response from the cache, or return the result of fetching the file.” The code after || will only be executed if the value before || is empty.
While that’s nice and short, I’m not sure it’s more understandable. Personally, I err on the side of trying to keep my code readable, even if that means the script is longer.
Putting it all together, you get something like this:
// When the browser requests a file...
addEventListener('fetch', fetchEvent => {
const request = fetchEvent.request;
fetchEvent.respondWith(
// First, look in the cache
caches.match(request)
.then( responseFromCache => {
if (responseFromCache) {
return responseFromCache;
} // end if
// Otherwise fetch from the network
return fetch(request);
}) // end match then
); // end respondWith
}); // end addEventListener
You’ve just made big performance improvements to your site. Anyone who visits your site more than once will have a speedy experience. Static assets are coming straight out of a cache, which means the browser doesn’t spend nearly as much time making network requests.
This all works wonderfully until you make a change to your CSS, or JavaScript, or some other static asset that you’ve put in your cache. The browser will never see the updated version. The updated file is sitting on your server, but in your service worker script, you’re instructing the browser to never look on the server for that file.
The solution is similar to what we do to update the HTTP cache: throw some versioning into the mix.
You might be tempted to change the file name of your service worker script and update your HTML to point to the new script. Don’t do that. Yes, a new service worker will be installed, but your old service worker will also still be installed. That’s a messy state of affairs.
Instead, you want to replace the outdated service worker with a new version. To do that, you’ll take care of versioning within the service worker script itself.
Your service worker script currently starts with the name of your static cache:
const staticCacheName = 'staticfiles';
Right before that, create a variable with a version number, something like this:
const version = 'V0.01';
It doesn’t really matter what you name this variable, or even what value you give it, as long as you can update the value whenever you want to update the cache. You could use the current date and time as your versioning variable, if you prefer. Whatever you choose, you can then add this versioning variable to your cache name:
const version = 'V0.01';
const staticCacheName = version + 'staticfiles';
If you change your CSS or JavaScript or anything else in your cache, edit the first line of your service worker script:
const version = 'V0.02';
Because you’ve made a change to your service worker script—even a small change like that—the install event will be triggered again when the browser checks to see if the service worker script has been updated.
Wait a minute…the service worker script is written in JavaScript. Your server is probably serving JavaScript files with a long cache lifetime. After all, you want most JavaScript files to be cached. The service worker file is an exception—you want the browser to check for a new version every time.
If you have access to your server’s configuration, it’s a good idea to add an exception for your service worker file. If you’re running an Apache server, you could add this to your .htaccess file:
<IfModule mod_expires.c>
<FilesMatch "serviceworker.js">
ExpiresDefault "access plus 0 seconds"
</FilesMatch>
</IfModule>
If you don’t have access to your server’s configuration, not to worry. Browsers make an exception for service worker scripts. Even if your server is telling the browser to cache all JavaScript files for weeks, months, or years, a service worker script will only be cached for a maximum of twenty-four hours. So even if you can’t explicitly change your server settings, the longest anyone will wait to get the updated version is one day.
If your server is set up to serve CSS and JavaScript with long cache lifetimes—as it should be—it’s not enough to only update the name of your static cache in your service worker script. While that will trigger the install event, it doesn’t mean that the files will be fetched directly from the server. The browser will fetch the files just as it normally does, which means it will check the HTTP cache first before going out to the network. Whatever strategy you’re currently using to break out of the HTTP cache, it still applies.
If you’re adding version numbers to your CSS and JavaScript file names, you’ll need to update the names of those files in your service worker script too:
return staticCache.addAll([
'/path/to/stylesheet-v2.css',
'/path/to/javascript-v3.js'
]);
Remember the service worker life cycle that we looked at in Chapter 3?
We can bypass that third step using the skipWaiting command in Chrome’s Developer Tools. Every time you make a change to your service worker script, you can click on that skipWaiting link to make sure your new service worker takes control immediately, without having to close your browser window.
You can bypass this waiting phase in your code, too, by telling the service worker to take control as soon as it is installed. Use the aptly named skipWaiting to do this:
addEventListener('install', installEvent => {
skipWaiting();
installEvent.waitUntil(
// Cache your files here
); // end waitUntil
}); // end addEventListener
The new service worker will take control as soon as it has been installed. The old service worker fades away into nothingness. You have removed the “waiting” step from the service worker life cycle.
When you’re testing on localhost and making lots of changes to your service worker script, there’s another very useful checkbox in Chrome’s Developer Tools: Update on Reload activates your updated service worker whenever you refresh the page.
But remember, not all refreshes are created equal. If you do a hard refresh (holding down the Shift key while you’re refreshing the page), then the browser will bypass the service worker completely.
Now you’ve got a way to trigger updates to your service worker—you change the version number at the top of your file:
const version = 'V0.03';
That will create a whole new cache called V0.03staticfiles:
const staticCacheName = version + 'staticfiles';
But the old caches don’t go away (Fig 4.2).
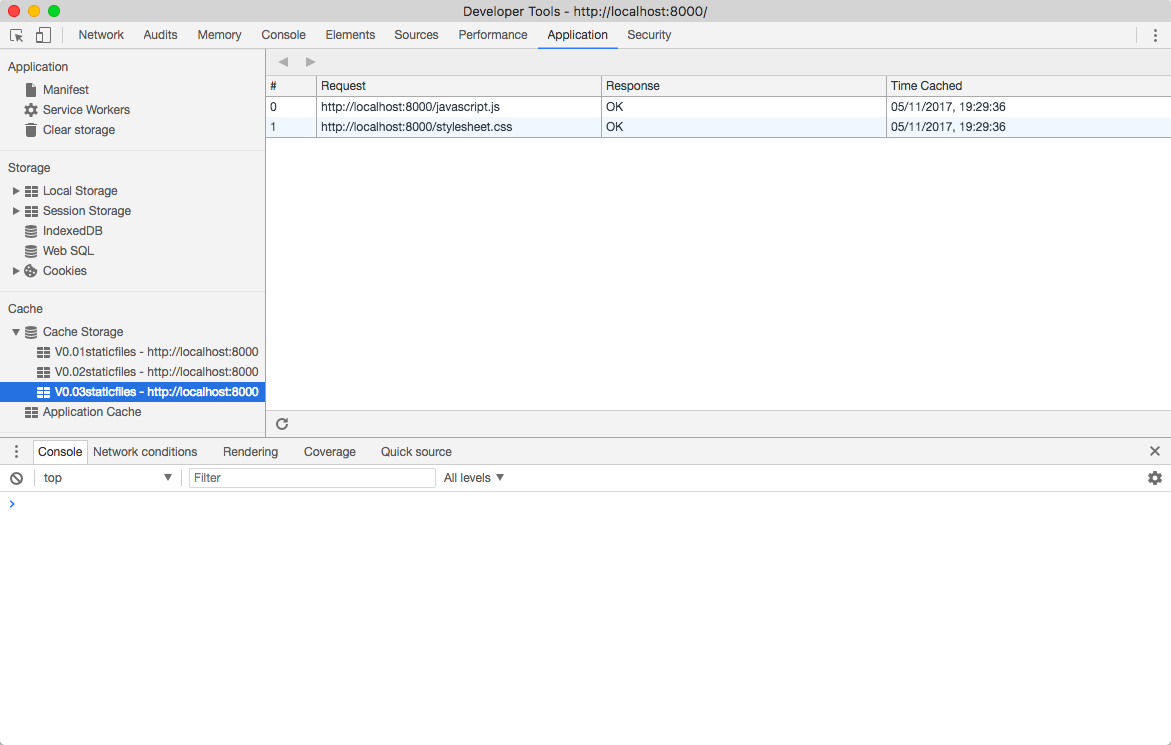
The browser doesn’t know that it’s never going to use those caches, so it’s up to you to take the garbage out. The moment that a service worker goes from installation to activation is the perfect time to take care of this—think of it as tidying up when you move into a new place. Best of all, there’s an event that fires at the moment of activation. You can use that event to trigger your clean-up:
addEventListener('activate', activateEvent => {
activateEvent.waitUntil(
// Clean all the things!
); // end waitUntil
}); // end addEventListener
I’m not going to lie—the code you need to write is going to get quite complex. Don’t worry if it doesn’t all make sense at first.
You can access the names of all your caches using the keys method of the caches object. It is—you guessed it—a promise:
caches.keys()
.then( cacheNames => {
// Loop through the cacheNames array
})
At this point, you need to loop through the values in the cacheNames array. But you can’t use a loop like you would in regular JavaScript code—that would be a synchronous operation. In service worker land, everything needs to be asynchronous, which means everything needs to be a promise. That’s okay—you can create your own promise and return its result (either a fulfillment or a rejection):
caches.keys()
.then( cacheNames => {
return Promise.all(
// Asynchronous code goes here
);
})
Using Promise.all allows you to wrap up a number of asynchronous operations in one return statement. All of the promises within must be fulfilled.
You’ve got an array called cacheNames that contains the names of all the caches. In the past, if I were going to loop through an array like this, I’d use something like a for loop. But in ES6, we’ve got a method called map, which is perfect for this situation. The map method is attached to the array. You can filter out the unwanted caches from the cacheNames array:
cacheNames.map( cacheName => {
if (cacheName != staticCacheName) {
// This cacheName needs to go!
}
});
The if statement will find any caches with names that don’t match the current static cache—notice the exclamation point that turns the question into a negative.
You can then delete each of those caches using the delete method of the caches object:
if (cacheName != staticCacheName) {
return caches.delete(cacheName);
}
You’re using a return statement because all of this is happening inside a promise. The return statement allows the promise to be fulfilled.
There’s one extra step you can take once all the old caches have been deleted. Normally when a service worker becomes active, it doesn’t take immediate control over any opened tabs. Instead, it waits for the user to either go to a new page or refresh the current page. That’s very well-mannered of the service worker; but if you don’t want it to be so deferential, you can instruct it to take control immediately.
The command for this is clients.claim. You can put this instruction in another then clause after you’ve dealt with old caches. With asynchronous events, chaining then clauses together is how you ensure that your code executes in the order you want.
In this case, there’s nothing to pass into the then clause, so there’s a pair of parentheses before the arrow instead. It looks like the worst emoticon ever:
.then( () => {
return clients.claim();
})
Putting it all together, your activation code looks like this:
addEventListener('activate', activateEvent => {
activateEvent.waitUntil(
caches.keys()
.then( cacheNames => {
return Promise.all(
cacheNames.map( cacheName => {
if (cacheName != staticCacheName) {
return caches.delete(cacheName);
} // end if
}) // end map
); // end return Promise.all
}) // end keys then
.then( () => {
return clients.claim();
}) // end then
); // end waitUntil
}); // end addEventListener
That looks quite complex. Don’t worry if you don’t understand all of it. To be honest, I don’t understand it myself. Please don’t tell anyone.
The truth is that your activation code and your installation code will remain largely unchanged from project to project. You can copy and paste code with only minor changes. If you don’t understand the code completely, that’s okay.
In short, use the install event to cache some files; use the activate event to delete old caches.
addEventListener('install', installEvent => {
// Cache some files
});
addEventListener('activate', activateEvent => {
// Delete old caches
});
But the code you write for the fetch event…well, that’s a different story. That code can be as unique as your website. That’s where the magic happens.
Service Worker Strategies